Análisis de sentimientos en archivos de audio
En este post se va a describir el estudio sobre técnicas existentes realizado para abordar el análisis de sentimientos.
Estudio técnico del problema
En primer lugar, se van a mostrar técnicas con las que se podría alcanzar la solución deseada.
En 2017, se propuso una técnica para determinar las emociones del audio basado en características espectro temporales de la señal utilizando convolucionales de 3 dimensiones. Para poder aplicar esta técnica, el método propuesto divide los audios en bloques de 2 segundos y extrae cada 20ms un espectrograma, creando al final un tensor de 3 dimensiones que define ese bloque. Ese tensor es la entrada de una red neuronal con convoluciones 3D que permiten extraer características, no solo del espectrograma sino de la relación temporal entre los segmentos. La ventaja de esta técnica es que no necesita utilizar ningún extractor de características de audio ya que la propia red se encarga de realizar esta extracción acorde a los sentimientos que trata de identificar [1].
Además de extraer características de audio para realizar correctamente el análisis de sentimientos basándose en la propia señal, se propuso en 2018 utilizar técnicas de descripción de textura aplicadas al espectrograma de la onda. Se evalúan diferentes algoritmos de extracción de características como filtros de Gabor, Histogramas de gradiente (HoG), la matriz de coocurrencia sobre los niveles de gris de la imagen (GLCM) y la descomposición de Wavelet. Al combinar características extraídas del audio, como son las características de Mel, con características obtenidas analizando la textura de los espectrogramas, los resultados obtenidos son superiores a los obtenidos de manera independiente [2].
Otra alternativa para extraer características de un audio teniendo en cuenta las relaciones temporales de los datos es utilizar redes neuronales que combinen capas convolucionales con capas recurrentes como la LSTM (Long Short Term Memory). En este contexto, se pueden utilizar convolucionales de 1D si utilizamos directamente la señal de audio, o convolucionales de 2D si se utilizan los espectrogramas de Mel [3].
En 2019, se propuso un método basado en el uso de modelos de aprendizaje automático aplicado sobre señales de audio normalizadas. La importancia de normalizar las señales de audio fue demostrada realizando diferentes configuraciones en los experimentos que dieron con el método final. Finalmente, el uso de redes neuronales convolucionales aplicadas sobre los datos normalizados teniendo en cuenta la normalización Z-Score fue el método con un mejor rendimiento. Esta normalización consiste en igualar la media de los datos a cero y escalarlos para obtener una varianza unitaria. Esta métrica es sensible a los outliers pero en este tipo de datos de sonido es difícil encontrar datos anómalos que no se puedan eliminar previamente en preprocesamiento [4].
Tipos de sentimientos humanos analizables
A lo largo del estudio de técnicas para el modelado de sentimientos a partir de audio y de bases de datos existentes, se han determinado que los sentimientos que se muestran a continuación son los más susceptibles de detectar en audios de conversaciones.
- Neutral
- Enfado
- Aburrimiento
- Asco
- Miedo
- Felicidad
- Tristeza
- Sorpresa
- Calma
Requerimientos de la señal de voz que permitan la identificación de sentimientos y comportamientos
Para que se pueda realizar el análisis sobre los audios de las conversaciones para la identificación de sentimientos, es estrictamente necesario que estos cumplan ciertos requisitos de calidad. Para ello, se va a determinar que deben de tener un índice MOS superior a 3. No obstante, este valor puede ser ajustado en un futuro durante la realización de pruebas.
Caracterización de la voz
La parte del proceso de extracción de características del audio es fundamental para la posterior identificación de sentimientos. Existen diversas técnicas mediante las cuales representar los audios para posteriormente poder ser analizados por diferentes modelos de Inteligencia Aritificial. la elección de uno u otro dependerá del formato deseado para el análisis de estas características. Los métodos más comunes son los siguientes:
- Espectrograma: devuelve una representación gráfica de los audios. Al tratar los audios como imágenes, permiten el uso de redes neuronales convolucionales, así como la aplicación de filtros de texturas.
- MFCC (Mel Frequency Cepstral Coefficients): método para extraer características de voz en audios que hace uso de la transformada de Fourier. Realiza un representación del audio mediante una serie de coeficientes y series temporales. Es ideal para la posterior aplicación de redes recurrentes como las LSTM.
- Centroide Espectral: medida estadística que informa sobre la forma que presenta el espectro, en especial su centro de gravedad. En este método, el espectro es considerado como una distribución probabilística determinada por la amplitud del espectro en cada frecuencia con el objetivo de obtener la frecuencia media ponderada de la amplitud.
- ZCR (Zero Crossing Rate): especialmente útil para detectar si en un audio determinado hay segmentos de voz. Se basa en calcular el número de cruces por cero en una señal.
- Spectral Roll-off: de nuevo, se considera el espectro como una distribución probabilística. El roll-off es un valor que debe ser superado en dicha distribución.
Variables cuantificables que puedan detectar estados de animo en una conversación
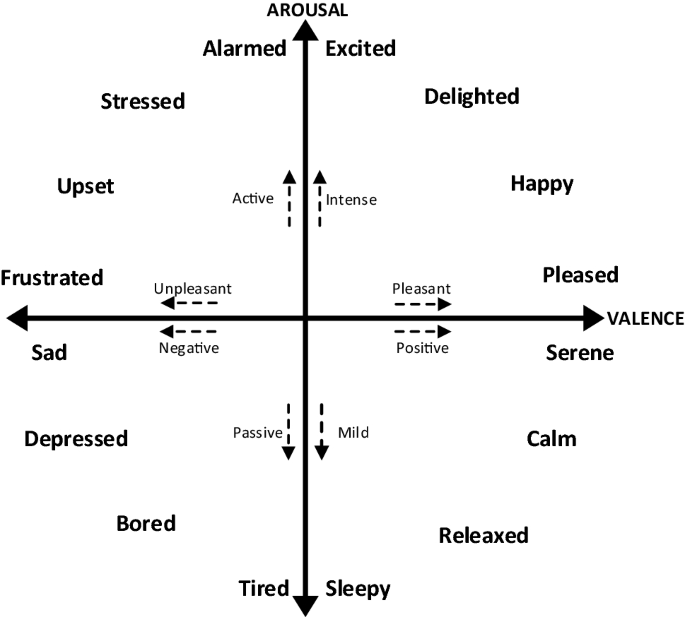
Existe la posibilidad de utilizar los valores de excitación (arousal) y valencia (valence) para determinar la emoción de un individuo en un determinado momento de una conversación con el objetivo de identificar la emoción transmitida. Esto es posible gracias a la creación de un diagrama de 2 dimensiones donde se representan ambas métricas. En función de la parte del cuadrante y la zona en la que sitúe el audio, se obtendrá un valor cuantitativo que reflejará la emoción transmitida, tal y como se puede ver en la siguiente figura:
Bibliografía
[1] J. Kim, K. P. Truong, G. Englebienne, and V. Evers, “Learning spectro-temporal features with 3D CNNs for speech emotion recognition,” in 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), 2017, vol. 2018-Janua, pp. 383–388.
[2] T. Özseven, “Investigation of the effect of spectrogram images and different texture analysis methods on speech emotion recognition,” Appl. Acoust., vol. 142, pp. 70–77, Dec. 2018.
[3] J. Zhao, X. Mao, and L. Chen, “Speech emotion recognition using deep 1D & 2D CNN LSTM networks,” Biomed. Signal Process. Control, vol. 47, pp. 312–323, Jan. 2019.

