Categorizar conversaciones basándose en el contenido
En el sistema implementado, se ha incluido una funcionalidad que es capaz de detectar la categoría a la que pertenece una conversación analizando el contenido de la misma. Para ello, se utiliza AI Platform donde se aloja un modelo previamente entrenado que realiza la predicción sobre un determinado archivo.
Cuándo utilizar esta funcionalidad
Esta funcionalidad es de gran utilidad a la hora de catalogar y categorizar diferentes conversaciones que se pueden producir en una empresa. La capacidad de etiquetar de manera autónoma las conversaciones que se realizan en una empresa puede facilitar tanto tareas de control de calidad como de gestión.
Esta funcionalidad es ad hoc. Para cada empresa que quiera utilizar nuestra funcionalidad de categorización de conversaciones, se realizará un entrenamiento concreto con sus conversaciones para identificar las categorías que más relevancia tienen dentro de su día a día.
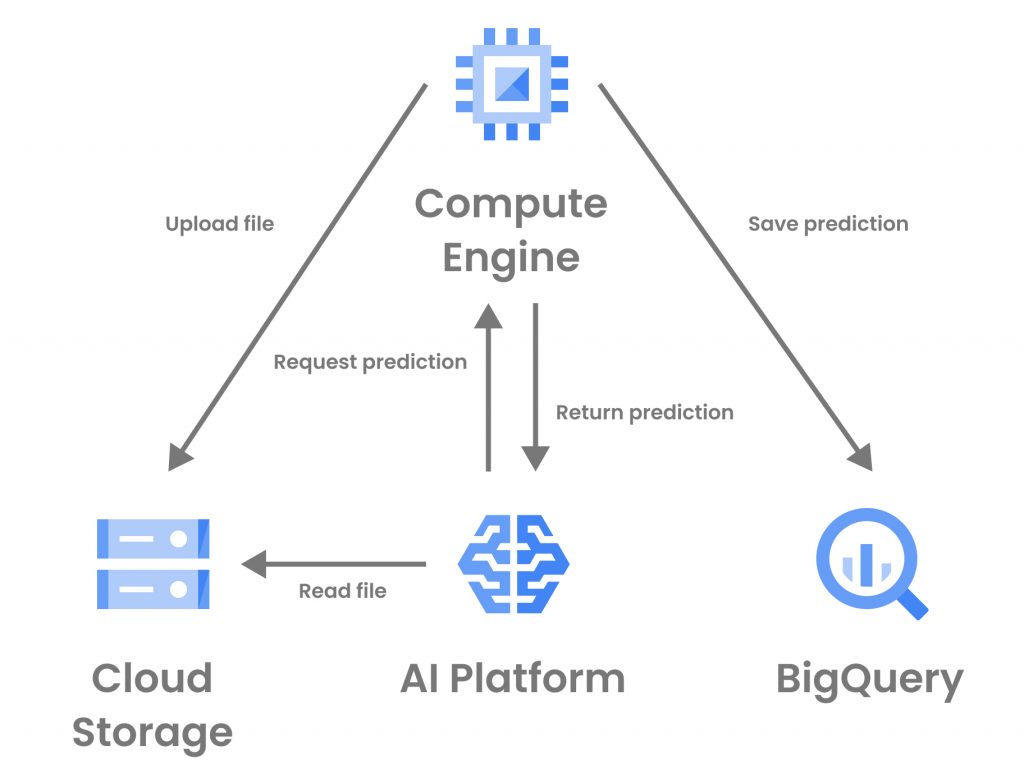
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de realizar la detección de sentimientos en un audio son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage.
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la determinación de la categoría del audio en función del contenido. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza el preprocesamiento de los audios y se realiza el speech-to-text para convertir el audio en texto.
Se realiza la predicción de los textos extraídos.
Se procesan las predicciones obtenidas y se devuelve la clase con un factor de confianza que identifica como de fiable es la predicción.
Se realiza la persistencia en BigQuery de la categoría obtenida por el modelo.
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de realizar la detección de sentimientos en un audio son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage.
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la determinación de la categoría del audio en función del contenido. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza el preprocesamiento de los audios y se realiza el speech-to-text para convertir el audio en texto.
Se realiza la predicción de los textos extraídos.
Se procesan las predicciones obtenidas y se devuelve la clase con un factor de confianza que identifica como de fiable es la predicción.
Se realiza la persistencia en BigQuery de la categoría obtenida por el modelo.
Identificar a las personas que participan en una conversación
El sistema incluye una funcionalidad que permite al usuario identificar inequívocamente a las personas que están involucradas en una conversación grabada. Para ello, utiliza el modelo de biometría previamente entrenado, que es capaz de extraer las características de un audio para generar un perfil biométrico del hablante. Mediante la división del audio en diferentes segmentos y obteniendo el perfil biométrico de cada uno de los segmentos, se puede determinar la identidad de todos los hablantes en la conversación.
Cuándo utilizar esta funcionalidad
En una llamada telefónica o una videoconferencia, puede ser de interés conocer quiénes son las personas que se vieron involucradas en dicha reunión. Gracias a ello, se puede conocer quiénes son las personas que suelen participar en reuniones en función del problema a tratar y cuáles son aquellas cuestiones que necesitan de determinados perfiles para resolverse. Por otro lado, también puede ayudar a determinar en empresas de atención al cliente cuáles son los trabajadores que requieren de más ayuda de sus compañeros para resolver una cuestión determinada.
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de determinar la identidad de los participantes en una conversación son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la identificación de los hablantes. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza la división en audios de un segundo y se preprocesan.
Se realiza la predicción de cada uno de los segmentos en los que se ha dividido el audio.
Se calcula la distancia entre las predicciones y se comparan para determinar la identidad de las personas que intervienen en el audio.
Se devuelve la identidad de las personas reconocidas en el audio.
Se devuelve la identidad de las personas reconocidas por el modelo.
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de determinar la identidad de los participantes en una conversación son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la identificación de los hablantes. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza la división en audios de un segundo y se preprocesan.
Se realiza la predicción de cada uno de los segmentos en los que se ha dividido el audio.
Se calcula la distancia entre las predicciones y se comparan para determinar la identidad de las personas que intervienen en el audio.
Se devuelve la identidad de las personas reconocidas en el audio.
Se devuelve la identidad de las personas reconocidas por el modelo.
Determinar la evolución del sentimiento de los interlocutores durante una conversación
En el sistema implementado, se ha incluido una funcionalidad que es capaz de detectar el sentimiento predominante en un audio o en diferentes partes de éste. Para ello, se utiliza AI Platform donde se aloja un modelo previamente entrenado que realiza la predicción sobre un determinado archivo.
Cuándo utilizar esta funcionalidad
A lo largo de una conversación los sentimientos y emociones de los participantes pueden ir variando. Un cliente puede llamar muy enfadado e ir calmándose a medida que se va solucionando el problema y acabar alegre. O puede llamar tranquilo y acabar enfadado por el trato recibido. Para una empresa con asistencia al cliente telefónica, ser capaz de determinar los sentimientos que generan sus empleados cuando hablan por teléfono con los clientes puede ser de gran valor.
Gracias a ello, pueden ser capaces de determinar cuáles de sus trabajadores son más eficaces a la hora de resolver problemas o cuáles son más propensos a enfadar a los clientes. Por lo tanto, esta funcionalidad es de utilidad en audios con una conversación en la que se requiere algo (ya sea una solución, información, confirmación..) de al menos una de las partes. Por ejemplo, no sería de utilidad en un audio con una lectura de un texto neutral, en el que no existe ningún tipo de emoción.
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de realizar la detección de sentimientos en un audio son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage.
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la detección de sentimiento. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza el preprocesamiento de los audios y se divide en el número de segmentos pasados como parámetro. En caso de que no se pase ningún número, el audio se deja completo.
Se realiza la predicción en cada uno de los segmentos preprocesados.
Se procesan las predicciones obtenidas y se devuelve el valor del sentimiento para cada uno de los segmentos.
Se realiza la persistencia en BigQuery del sentimiento/sentimientos obtenidos por el modelo.
Pasos y arquitectura
Los pasos seguidos por el programa a la hora de realizar la detección de sentimientos en un audio son los siguientes:
Subir los audios pasados como parámetro a Google Cloud Storage.
Llamar al modelo desplegado en AI Platform con una rutina de predicción personalizada para la detección de sentimiento. En dicho modelo tendrán lugar los siguientes pasos para cada uno de los audios que se pasan como parámetro:
Se lee el audio de Cloud Storage con librosa.
Se realiza el preprocesamiento de los audios y se divide en el número de segmentos pasados como parámetro. En caso de que no se pase ningún número, el audio se deja completo.
Se realiza la predicción en cada uno de los segmentos preprocesados.
Se procesan las predicciones obtenidas y se devuelve el valor del sentimiento para cada uno de los segmentos.
Se realiza la persistencia en BigQuery del sentimiento/sentimientos obtenidos por el modelo.
¿Conoces el valor de tus audios?
Transforma tus grabaciones de audio en insights y mejora la rentabilidad y la toma de decisiones.
Cuéntanos tu caso y un consultor te asesorará sin compromiso sobre cómo obtener todo el valor que se esconde en tus archivos de audio.
¿Conoces el valor de tus audios?
Transforma tus grabaciones de audio en insights y mejora la rentabilidad y la toma de decisiones.
Cuéntanos tu caso y un consultor te asesorará sin compromiso sobre cómo obtener todo el valor que se esconde en tus archivos de audio.